Pandas. Шпаргалка
Pandas — это мощная и гибкая библиотека для манипуляции и анализа данных в Python. Она предоставляет структуры данных и функции, необходимые для работы с структурированными данными.
Pandas Шпаргалка 2023 - Краткое руководство
Основные концепции Pandas
Pandas - это мощная библиотека Python для анализа и обработки данных. Вот ключевые компоненты:
Основные структуры данных
1. Series - одномерный массив с метками
2. DataFrame - двумерная таблица данных (как электронная таблица Excel)
Основные операции
Создание структур данных
import pandas as pd
import numpy as np
# Создание Series
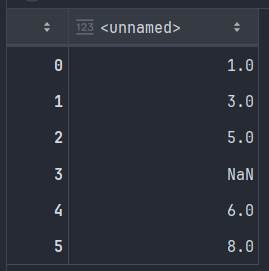
s = pd.Series([1, 3, 5, np.nan, 6, 8]) # np.nan - не число (not a number)
# Создание DataFrame
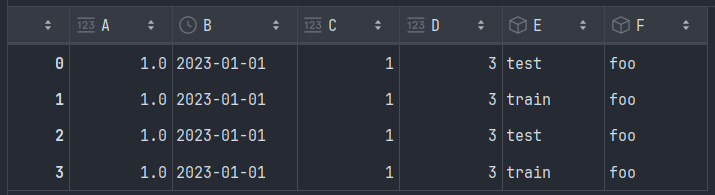
df = pd.DataFrame({
'A': 1., # число с плавающей точкой (float)
'B': pd.Timestamp('20230101'), # столбец с временной меткой 2023-01-01
'C': pd.Series(1, index=list(range(4)), # Series с одним значением 1 и индексами от 0 до 3
'D': np.array([3] * 4), # массив из 4 элементов (значение 3)
'E': pd.Categorical(["test", "train", "test", "train"]), # столбец с категориальными данными
'F': 'foo' # строковое значение 'foo' для всех строк
})out[\(s\)]
out[\(df\)]
Чтение данных
# Из CSV
df = pd.read_csv('file.csv')
# Из Excel
df = pd.read_excel('file.xlsx')
# Из SQL
from sqlalchemy import create_engine
engine = create_engine('sqlite:///:memory:')
df = pd.read_sql('SELECT * FROM table', engine)Запись данных
# В CSV
df.to_csv('output.csv', index=False)
# В Excel
df.to_excel('output.xlsx', index=False)
# В SQL
df.to_sql('table_name', conn, if_exists='replace', index=False)Просмотр данных
df.head() # первые 5 строк
df.tail(3) # последние 3 строки
df.shape # размерность (строки, столбцы)
df.info() # информация о типах данных
df.describe() # статистика по числовым колонкамРабота с DataFrame
Выбор данных
# Выбор столбца
df['column_name']
df.column_name
# Выбор строк по индексу
df.loc[0] # по метке
df.iloc[0] # по позиции
# Выбор по условию
df[df['column'] > 0.5]Фильтрация данных
# Фильтр по значению
df[df['quality'] == 6]
# Фильтр по нескольким условиям
df[(df['quality'] > 5) & (df['alcohol'] < 12)]
# Использование isin()
df[df['column'].isin(['val1', 'val2'])]Обработка пропущенных значений
df.isna() # проверка на NaN
df.dropna() # удаление строк с NaN
df.fillna(0) # замена NaN на 0
df.fillna(df.mean()) # замена на среднееГруппировка и агрегация
# Группировка
grouped = df.groupby('column')
# Агрегация
grouped.mean()
grouped.agg(['mean', 'min', 'max'])
# Сводная таблица
pd.crosstab(df['col1'], df['col2'])Объединение данных
# Конкатенация
pd.concat([df1, df2])
# Слияние (как JOIN в SQL)
pd.merge(df1, df2, on='key')Визуализация данных
Pandas интегрируется с Matplotlib для визуализации:
import matplotlib.pyplot as plt
# Линейный график
df.plot()
# Гистограмма
df['column'].plot.hist(bins=20)
# Диаграмма рассеяния
df.plot.scatter(x='col1', y='col2')
# Ящик с усами
df.plot.box()
# Сохранение графика
plt.savefig('plot.png')
plt.show()Полезные методы
Применение функций
# Применение функции к столбцу
df['column'].apply(lambda x: x*2)
# Векторизованные операции
df['new_col'] = df['col1'] + df['col2']Сортировка
df.sort_values('column') # по возрастанию
df.sort_values('column', ascending=False) # по убываниюВременные ряды
# Преобразование в datetime
df['date'] = pd.to_datetime(df['date'])
# Ресемплинг
df.resample('M').mean() # по месяцамСоветы по оптимизации
1. Используйте векторные операции вместо циклов
2. Для больших данных используйте dtype с меньшим объемом памяти
3. Применяйте eval() и query() для сложных выражений
4. Используйте category тип для строковых данных с малым числом уникальных значений
df['category_column'] = df['category_column'].astype('category')Это основные концепции Pandas, которые помогут вам эффективно работать с данными в Python. Библиотека предлагает гораздо больше возможностей, но этого набора хватит для решения большинства задач анализа данных.